

No one tells you this, but Data Science is a game of compromise.
In school, analysis—no matter how complex—almost always had a clear path.
You just had to dig to find it.
But in real life, there’s too much randomness, too much ambiguity, and rarely enough time or resources to follow the “ideal” path.
I would argue, this is the REAL hard part of doing analysis in the real world, not writing Python or SQL, or deciding which model is best, but instead:
The pre-planning
Adjusting to constraints without losing sight of the objective
Aligning with stakeholders in a clear way
And in the past, this is where I’d get stuck.
I’d open a document, try to structure my thoughts, maybe sketch out a plan… and end up jumping straight into the code just to feel like I was making progress.
But lately, I’ve been doing something different.
Something that’s helped me think sharper, stress less, and deliver more polished work—without adding extra overhead.
In fact, I’d say this new workflow has 10x’ed my work.
And today, I want to share exactly how it works.
Context is all you need
Most people using ChatGPT ask one-shot questions and then get frustrated when it doesn’t magically fix all of their problems.
The reason it doesn’t work that well is because it lacks enough “context“.
Without it, ChatGPT becomes a guessing machine.
With it, it becomes a collaborator.
And this is what the most efficient way of doing this looks like:
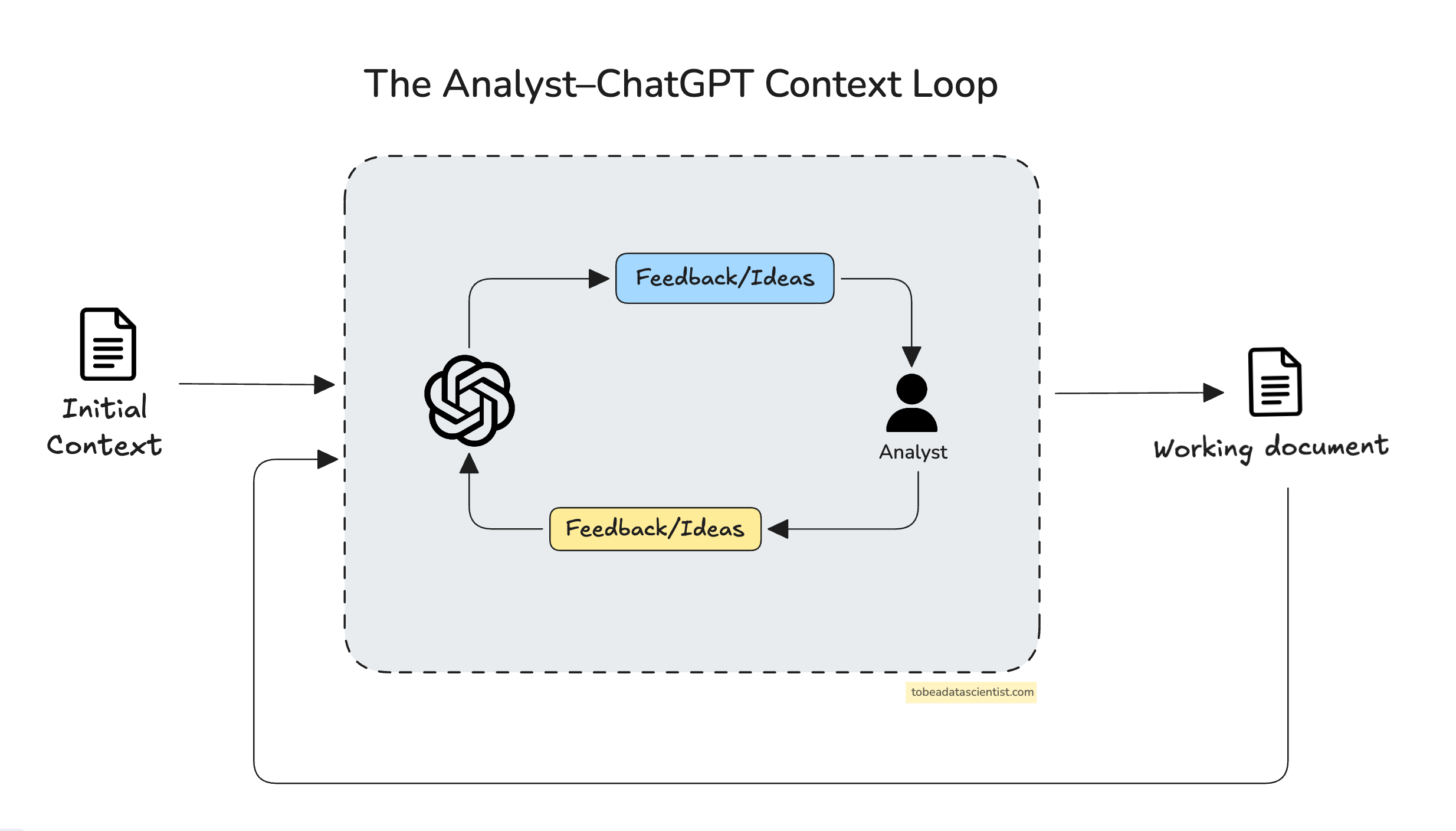
This is the foundation of my workflow, and it involves giving ChatGPT real context from the beginning and then letting it help me generate drafts, ideas, or code, so that I can then take that output, refine it, and feed it back in to keep moving forward.
Let me show how it works in practice.