


How to Structure Your Data Science Notebooks So People Don't Hate You
Make your analysis easy to follow and reproduce

What the hell!
That’s my reaction every time I open a colleague’s notebook and realize that I’m better off starting the entire analysis from scratch than trying to decipher the sorcery they did.
And this sucks even more when the person has already left the company, so you don’t have the ability to confront ask them.
There goes their days or weeks of work down the drain.
But you know what, my notebooks used to be terrible too. I’ve been through several phases throughout the years:
The “The more, the better” phase: Creating incredibly detailed and lengthy notebooks no one will ever read, thinking that the more information I included, the more valuable it was. This was basically me all throughout university.
The "ship fast or miss out" phase: Treating Jupyter notebooks like scratch paper, delivering insights fast, but then realizing that I could never reuse more than 20% of my work.
The "I take pride in my work" phase: Trying to provide the best quality work possible, always prioritizing reusability, and more often than not, struggling to deliver insights fast enough.
Needless to say, these approaches were all bad.
But finally, for the past 2 years (after only 5 years of failed attempts) I’ve found a structure that strikes a great balance between clarity, reusability, and speed.
And believe me, this is a skill you don’t want to neglect as it will be relevant all throughout your career:
When doing projects for your portfolio
When a company you are interviewing for gives you a take-home assignment
And of course, when doing analysis at work
Today I’ll share my framework for structuring notebooks in a way that makes analysis efficient, easy to follow, and reproducible, while still allowing you to deliver insights quickly.
What we’ll cover in this guide:
Guiding principles
Structuring your Data Science notebooks
When to split your notebooks?
Jupyter Notebook Template (Download)
Guiding Principles
Let’s establish some guiding principles that will help us make the best decisions when working with notebooks.
1—Embrace the Iterative Process
Don’t expect analysis and model-building to happen in a neat, sequential manner.

In the real world, you’ll constantly revisit your work, make adjustments, and refine your assumptions as you discover new insights.
For example, after your initial round of EDA, you’ll often find yourself going back to tweak preprocessing steps—normalizing columns or handling outliers you didn’t anticipate in the beginning.
Ensure this iterative nature is reflected in how you structure and document your work. Don’t just adjust your code, make sure your notes and descriptions evolve as well, so your analysis stays clear and up-to-date with each iteration.
2—It’s only a proof of concept
Don’t mistake your notebook for the final product.
The true business value comes after you’ve shared your insights or your model has been deployed and used.
Treat your notebook as a proof of concept and don’t get hung up on perfecting every line of code and documenting every single step in your approach.
Make it good enough for feedback, and avoid overcomplicating things more than necessary.
3—Version control matters
Your notebook shouldn’t just live on your local machine.
While version control for notebooks doesn’t always track every change seamlessly, it’s still a useful tool to document progress, share your work, and ensure others can access it.
The main benefit isn’t necessarily about rolling back mistakes but about making your work available for collaboration, feedback, and reproducibility.
It’s a simple habit that builds transparency and makes your work more valuable in a team setting.
Structuring your Data Science notebooks
It doesn’t matter which notebook environment you are using, whether it’s Jupyter Notebook, Google Colab, Databricks notebook, or any other variation out there, you need to have a clear and consistent approach to how you structure your analysis.
Here is the best structure I’ve found over the years:

This base structure works great for most analysis you will do as a Data Scientist, but of coarse, you can adjust it as necessary to fit your specific needs.
Why does this work great for most situations? Two reasons:
Single notebook: Keeping everything contained within a single notebook, makes it easy to follow and review.
One section per major task: It ensures each major task in your analysis is clearly separated into its own section for easy navigation and clarity.
When should you split your notebooks?
This is a question every data scientist is inevitably faced with at some point in their career.
Now, if you remember anything from our guiding principles is that our notebooks are just a proof of concept and we should avoid overcomplicating things at all cost, which tends to happen when we split notebooks and have to manage multiple files.
But sometimes your projects grow so much in complexity that it simply doesn’t make sense to contain everything in a single giant file that takes forever to run.
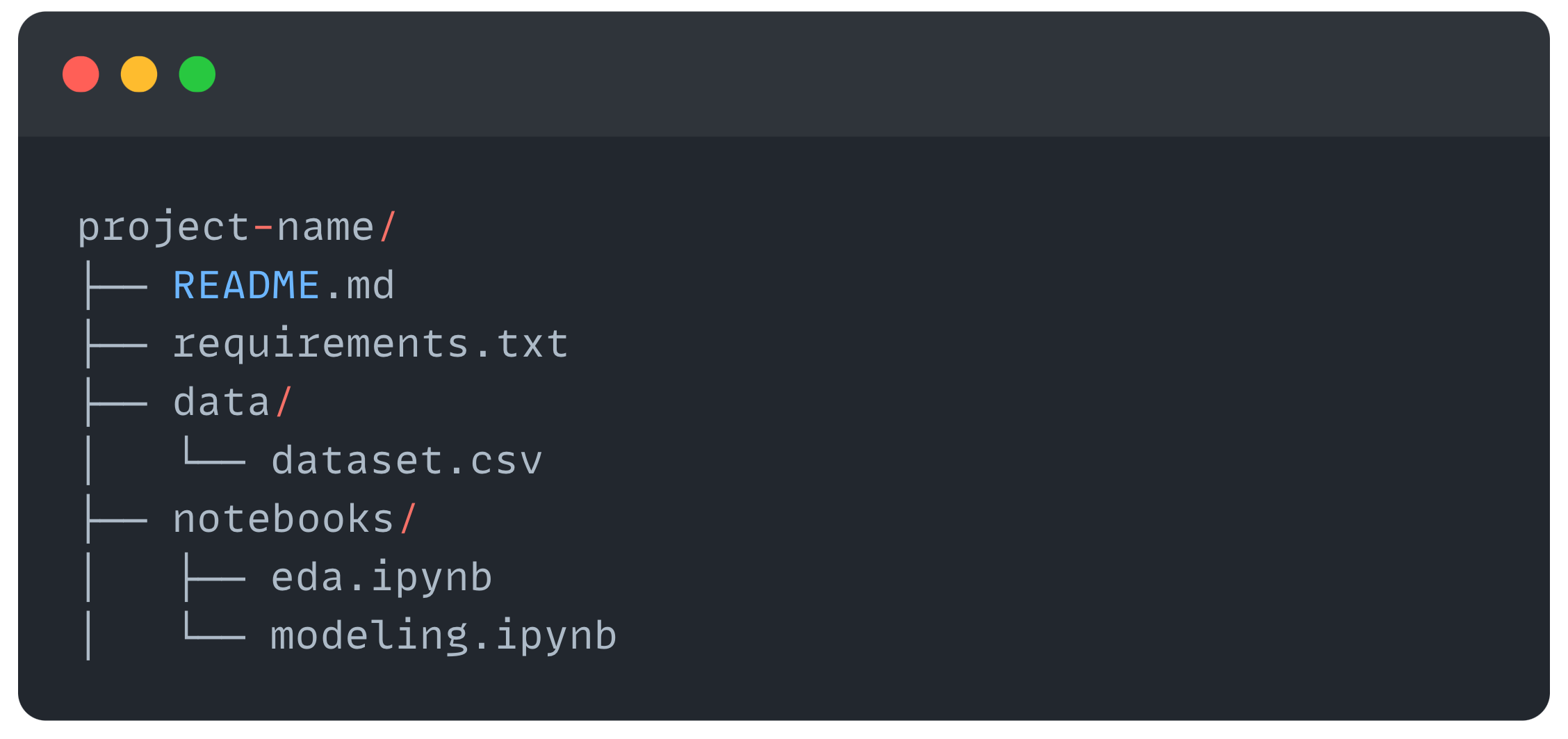
So keep this in mind:
For smaller projects such as doing EDA or training a linear regression model, keeping everything in a single notebook avoids unnecessary complexity.
For complex projects such as building a recommender system or neural network, splitting by major tasks (e.g., EDA, preprocessing, modeling, evaluation) ensures modularity and makes it easier to debug, collaborate, and maintain the code.