

Understanding and leveraging NLP continues to be an incredibly valuable skill for Data Scientists.
And more so now that it is hugely in demand across multiple industries.
But this is 2025, and plotting word clouds won’t get you far, the expectations are much higher!
Transformers, the neural network architecture introduced in the Attention is All You Need paper in 2017, are now the backbone of state-of-the-art NLP solutions.
And the best way to get hands-on experience with Transformers models (such as LLama 3.3 or GPT-2) is by using Hugging Face’s Transformers library.
With it, you’ll have access to pre-trained models that you can deploy locally or fine-tune for NLP tasks like classification, summarization, text generation, and others.
So let’s get started!
Here is what we’ll cover:
What is the Hugging Face Transformers library?
Method 1: Using the pipeline API
Method 2: Using AutoTokenizer and AutoModelForCausalLM
Demo: Access to a Google Colab so you can try it out yourself
What is the Hugging Face Transformers library?
Transformer models are usually very large, we are talking millions to tens of billions of parameters, which means training and deploying these models is no easy task.
Just to give you a sense of the scale, Llama 3.1 has 405 billion parameters!
So the goal behind the Transformers library is to provide a single API through which any Transformer model can be loaded, trained, and saved.

The Transformers library is available as a Python package and all you need to do to install it is:
pip install transformersSo now, let’s explore the two ways in which you can access these Transformers models via the Transformers library
pipelineAPIAutoTokenizerandAutoModelForCausalLM
Method 1: Using the pipeline API
The pipeline API is the easiest way to get started with Hugging Face. It abstracts away much of the setup, allowing you to focus on the task at hand.
Example: Text Generation
Here's how to generate some text using a lightweight model like GPT-2:

A bit of an explanation:

Why Use pipeline?
Beginner-friendly: No need to load models or tokenizers manually.
Quick setup: Perfect for standard NLP tasks like text generation, sentiment analysis, and summarization.
💡 By the way, for all these examples I’m using GTP-2 since its a small model that doesn’t require a GPU.
Method 2: Using AutoTokenizer and AutoModelForCausalLM
For more control over how the model processes inputs and generates outputs, use AutoTokenizer and AutoModelForCausalLM.
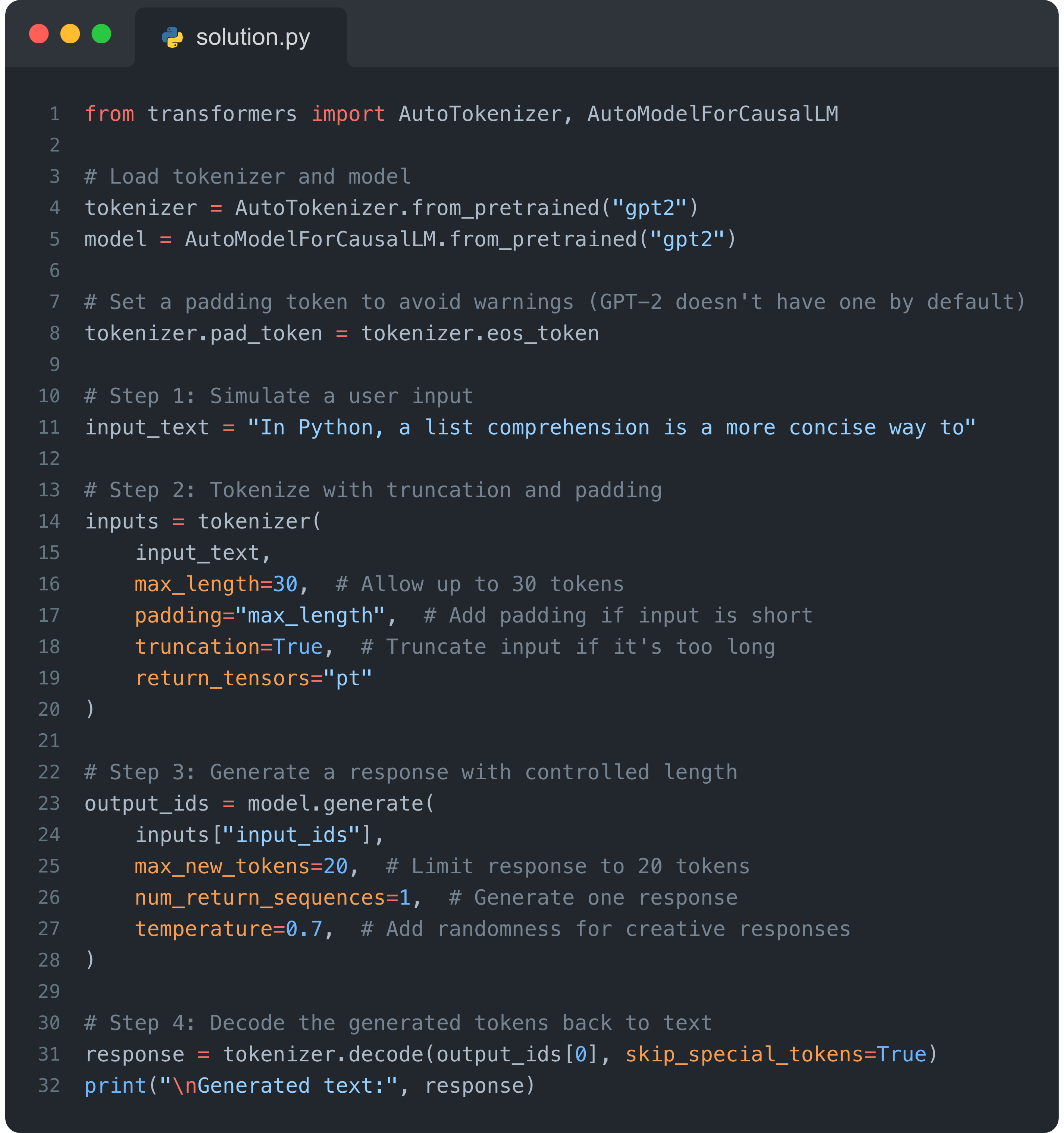
Example: Text generation
Here’s how you can generate text with GPT-2 manually:

Now, at first glance, this may seem like we just added more lines of code to get virtually the same output you could’ve gotten using .pipeline(), and you would be right, but the true advantages of this setup come from how you configure your tokenizer and model.
Imagine you're building a chatbot. You want:
To preprocess user inputs (e.g. truncate long messages, pad short ones).
To ensure the chatbot generates responses that don’t exceed a certain length.
To handle user-specific quirks (e.g. typos, informal speech).
Handling that would look something like this:
Why Use AutoTokenizer and AutoModelForCausalLM?
Flexibility: Fine-tune tokenization or adjust model parameters.
Advanced use cases: Ideal for workflows that require customization or integration into larger pipelines.
Try it out yourself
If you want to run the code I showed as examples, check out the Google Colab here.

Final Thoughts
Hugging Face makes NLP accessible for a wide range of needs, from simple to advanced.
By understanding the difference between the pipeline API and the more customizable AutoTokenizer and AutoModel methods, you can leverage this powerful library for a wide range of NLP tasks.
For more resources, I highly recommend you check out the Hugging Face NLP course., it has been incredibly valuable to my own technical development.
Thank you for reading! I hope this article helps you upskill and stay relevant as a Data Scientist.
See you next week!
- Andres
Before you go, please hit the like ❤️ button at the bottom of this email to help support me. It truly makes a difference!